Semantic, Structured Authoring
By
Tony Self
Introduction
Sir Tim Berners-Lee is passionate about something he calls the
"Semantic Web". Well respected as the inventor of the World Wide Web,
Berners-Lee recognises the deficiencies of HTML, and sees the solution
lying in the power of XML. Extensible
Markup Language is a standard
developed and maintained by the World Wide Web Consortium (W3C), an international
committee that guides the World Wide Web "to its full potential by
developing protocols and guidelines".
Despite being produced by the W3C, it would be wrong to think of XML
as a Web enterprise. XML is bigger than the Web. XML is a format for
storing all types of data, and that includes "information", "content",
instructions, procedures, stories, and ideas. It is a format for storing
knowledge. It will be the format for DVD settings, phone directories,
cricket statistics, traffic light sequences, spacecraft design, Help
systems and procedure manuals. For technical writers, this is not some
insignificant development. Nor is it something technical for only
programmers to worry about. It requires a change in the way we write, and
in the processes we use to write.
This article looks at the impact of the introduction of semantic
markup and structured authoring on the world of technical writers,
editors, Help authors and content developers. This article is not
specifically about the Semantic Web movement itself,
but about the implementation of semantic concepts in the documentation
field.
This article was first published in January 2005, and revised and
updated in March 2007.
The "Semantic Web"
So what does Berners-Lee mean by the term "Semantic Web"? To quote
the man himself, the Semantic Web is "an extension of the current Web in
which information is given well-defined meaning, better enabling computers
and people to work in co-operation". That helps a little. An overly
academic explanation explains "the attempt to augment syntactic
information already present in the Web with semantic metadata in order to
achieve a Semantic Web that human and software agents can
understand."
Perhaps a better explanation is that the "Semantic Web" is an
attempt to make the information on the Web behave more like a text
database, where information is better categorised, structured, organised
and labelled. Rather than describe a blob of information as simply a
paragraph (through an HTML <p> tag), it may describe the same blob
by its nature, such as water quality (through an XML <water_quality>
tag). The content is contained within tags that describe the information
within.
A Semantic Web would therefore be much easier to work with; for
machines and humans to process, re-organise, re-use, re-format and
comprehend.
Metadata
Metadata is data about data. Information that describes or
classifies information. Even if we've never used the term "metadata"
before, we've actually know it well. An index is metadata. It helps
describes the information, but it is not part of the core information
itself. The details of a novel's publisher is part of a novel's metadata.
It's not part of the story, but it is important information.
The name of the person who approved a company policy is part of that
policy's metadata. The release date of a Help system is metadata. Now
wouldn't it be great if we could locate information based on a
comprehensive, well thought out collection of metadata? It'd be like using
a super-indexing system. Wouldn't it be great if we could "Google" for a
sea kayak reseller in Melbourne with Sunday opening hours, and find one or
two results, not 688? (Don't believe me? Check
what Google really returns .)
Metadata is important to the concept of the "Semantic Web". It is
just as important to non-Web information.
Where Does XML Fit In?
XML is the technology underpinning the "Semantic Web". It provides
the rules framework for storing, retrieving and displaying information,
not just for the Web, but for use within software applications, and for
creating printed documents.
XML is not really a language in itself, but a set of rules for
creating languages. There is an XML language called CML, designed for
storing and displaying information about chemicals. There is an XML
language called MathML, designed for storing and displaying mathematical
formulae. There is an XML language called WML, designed for storing
information for display on mobile phones. There is an XML language called
DocBook, designed for storing procedure manuals and other forms of
documentation. AML is another XML language, designed for storing and
displaying user assistance information for the Help system for Windows
Vista.
We would recognise some of these XML applications as pure "data"
storage formats. But others we would identify as "document" or information
storage formats. One more example might help explain this distinction. An
XML language called "Office Open XML" is a format now used by Microsoft
Word and Excel to store word processing documents and spreadsheets. The
old RTF-based .doc format is a thing of the past.
XML offers a technical solution to a very human communication
problem. In the Information Age, we are overwhelmed by quantity of
information, but underwhelmed by the quality!
The Challenge for Technical Writers
The world is awash with information, and we have all experienced the
symptoms of " information
overload ". Attention spans are reducing. Readers are becoming
more impatient, and are wanting to quickly scan information rather than
read it thoroughly. As creators of information, of content, technical
writers need to confront this problem.
The tried and trusted narrative style of writing, where we open an
empty page and start writing, is no longer appropriate. The standards we
previously worked within are no longer sufficient. We need to have more
formal hierarchies and structures for our information; it needs to be more
granular, and it needs to be framed in metadata.
Semantic, Structured Authoring
The Macquarie Dictionary defines semantic as "pertaining to
meaning". Semantic Authoring aims to give more meaning to the information
being written. If we are going to not only write down the words we want to
communicate, but at the same time describe what it is we are writing, then
we have to adopt a structured approach to writing.
For example, if we are writing a procedure which states that the
address section of a form must be completed, it is just as important to
describe this part of the procedure as a step (or a rule, or a policy, or
a legal requirement), and to describe the circumstances when this
instruction applies.
In short, once we start to provide a semantic overlay to our
writing, we find we need to use structures to work within. In the example
above, being able to "tag" the instruction as <policy> or
<step> would give the instruction its semantic "key". So that our
writing is consistent, and so that the semantics of our work can be used
for indexing, or searching, or some retrieval, we would need to decide on
a standard range of "tags". If we wanted to collaborate with other
writers, then we would need to negotiate and agree on that standard set of
tags.
In fact, that process has already happened. IBM pioneered a standard
called DITA, which defines a "tag" structure suitable for authoring,
producing and delivering technical information. DITA stands for Darwin
Information Typing Architecture, and was developed by technical writers.
(By the way, the "Darwin" is a homage to the evolutionary theorist Charles
Darwin, because DITA uses the principles of specialisation and
inheritance.) DITA is now an open standard, and is guided by a committee
of technical writers. The types of tags in DITA include
<topic>, <title>,
<shortdesc>, <prolog>,
<body> and <concept>.
DITA is, of course, an XML language. The rules for XML languages are
formalised in a "Document Type Definition" (DTD) or "schema". DITA isn't
the only XML schema on offer for technical writers. DocBook is
another.
DocBook is another open standard, designed for technical
documentation. It has tags such as <article>,
<section>, <title>,
<articleinfo> and
<pubdate>.
Writing to an XML schema is similar to filling in a form, and this
is the primary distinction between "structured authoring" and the
traditional "narrative authoring". You don't start with a blank page; you
start with an empty form. You don't work within the hard-to-enforce rules
of a style guide; you work within the strict rules of a schema. In
narrative (sometimes called "style-based" or "template-based") authoring,
the structure of the document is implied by its typography. In structured
authoring, the structure of the document is explicitly defined by its
tags.
Separation of Content from Presentation
One of the original principles of the World Wide Web was the
separation of content from presentation. The idea was that the author
would provide a simple structure for the document by using a simple set of
tags (<h1>, <h2>,
<p>, etc), and the viewing program (or browser)
would determine how that information was presented to the reader. The
author didn't define how an <h1> heading would be
presented - the browser software did. Most browsers were designed so that
the reader could override the default settings, giving the reader the
power to choose how a document looked.
Unfortunately, this principle was lost in a period known as the
"browser wars", where new browser-specific tags were added without the
consent of the W3C. Once the <font> tag was
introduced, the separation of content from presentation ideal was diluted.
Trying to shut the gate after the horse had bolted, the W3C eventually
introduced the concept of Cascading Style Sheets (CSS), which
re-invigorated the idea of separating content from presentation. If you
have never looked at the CSS Zen Garden, then do so now.
It is a CSS showcase, where just one page of content is presented in
hundreds of different ways just by linking to different style
sheets.
XML not only re-introduces the concept of separation of content from
presentation, but takes it to a new level. The tags used in HTML were
really presentational tags. By nominating a paragraph as
<h1>, the author was really defining an aspect of
the presentation to the reader. An <h1> was a
heading. A heading is a presentation or formatting term more than a
content term. An XML schema allows more specific tags, such as
<concept> and <conbody>,
to be used. No inference about presentation can be drawn from those tags.
So presentation can be truly separated from content. XML tags and their
attributes contain the document's metadata.
Writers write the content. Someone else decides on the
presentation.
Separation of Content from Delivery
The most powerful technical benefit of XML is the ability to also
separate content from delivery. When we write a structured XML document,
we don't need to concern ourselves with how the information will be
delivered to the reader. Will it be delivered as a paper document? As a
PDF? On a Palm Pilot or other PDA? As a CHM file? As a Web page? In a
specialised browser? Within Microsoft Excel? It doesn't matter.
Writers write the content. Someone else works out how it will be
delivered to the reader.
This concept is fairly new to the technical writing world, but isn't
so new in other writing professions. Newspaper journalists submit stories
(in an XML format normally) to their editors. They write the stories on a
computer, and they have no say in formatting or delivery decisions. A news
story may end up being syndicated to a specialised Web site in Singapore,
it may be printed on the front page of the "Sydney Morning Herald", parts
of it may be sent as an SMS message to news subscribers, or it might end
up on the Fairfax Web site. The story may be presented in 14 point Times
Roman, or it might be in 6 point Tahoma. Journalists write the content.
Someone else takes care of presentation and delivery.
Knowledge Markup
Semantic authoring has been defined as "to compose information
content semantically structured according to some ontology". (If you've
never encountered the word ontology before, the
dictionary defines it as "the branch of philosophy concerned with the
nature of being".) A much better explanation of semantic authoring is
"knowledge markup". Simple tags such as <policy>
aren't the only way in which knowledge is categorised, indexed and
labelled within XML. Tags can contain attributes (such as the id attribute
in <section id="upg11">), and metadata can be
stored in tags separate from the content itself (such as
<author><firstname>Tony</firstname><surname>Self</surname></author>).
Authoring Tools
If we are going to write our procedures, instructions, policies or
Help content into an XML format, we are probably going to need an
authoring tool. XML documents are stored in ASCII format, so in theory, we
could use Notepad as our editor. Alternatively, we could use a more
specialised XML editor, or even an HTML editor (most can cope with XML
code).
The determining factor, though, is what schema we are writing to. If
we are writing to DocBook, it would be best to use a tool that is
"DocBook-aware". If we are writing to the Chemical Markup Language
standard, we should write using a "CML-aware" tool. Most XML authoring
tools on the market tend to be generic, rather than specific to a
particular XML language.
As a language becomes more popular, the demand for a specific tool
rises, and the market fills the need. XML being an open standard, and XML
documents being stored in ASCII, it is easy to chop and change between
tools. The screen capture below shows a quickly-assembled editing tool for
an in-house XML standard used for online Help. If you look closely, you
might recognise the application as being a Microsoft Access form. Access
can save content to XML, using the database field names as XML tag names.
In the example, the information in the Title field will
be saved within a <title> tag.
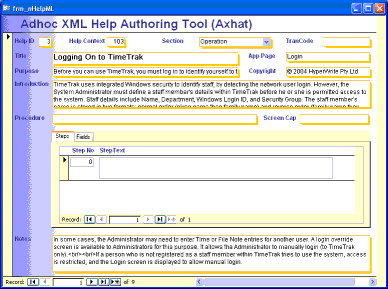
Screenshot of XML Authoring Tool
The most common semantic markup languages for documentation are
DocBook and DITA. PTC Arbortext Editor, JustSystems XMetaL, Syntext Serna,
XMLmind XXE, DITA Storm, or perhaps OpenOffice, are good choices for
authoring documentation content; some tools support DITA, others DocBook,
and others both. And these tools are growing in sophistication and
maturity rapidly.
There's no reason why technical writers can't start writing their
content in DocBook, or DITA, or a custom XML language for that matter,
now. In fact, many already are. (This article was written in DocBook.) But
what about the writing skills and techniques? Are they the same as for
narrative authoring?
Structured Authoring Techniques
Structured authoring is a concept or methodology, and XML is one of
the technologies through which structured authoring is implemented.
(AuthorIT and Adobe Structured Framemaker is another alternative to XML.)
Writing within an XML structure is like filling in a form. There are some
parts of the form that we have to fill out, other parts that we need to
expand upon, and other parts that are not relevant. The XML schema
specifies what elements are compulsory, which ones can be repeated, which
ones are optional, and the hierarchy of those elements. Once we commit to
writing to a schema, we cede control of these elements. If our content
doesn't seem to fit the schema rules, we have to make it fit!
Writing structured content takes some time to get used to. Research
by Adobe Systems indicates that that structured authoring is initially
more expensive, but quickly becomes very efficient. The graph below shows
the relative cost of structured (they call it Single-Source Authoring)
versus Unstructured Authoring over the life of a document.
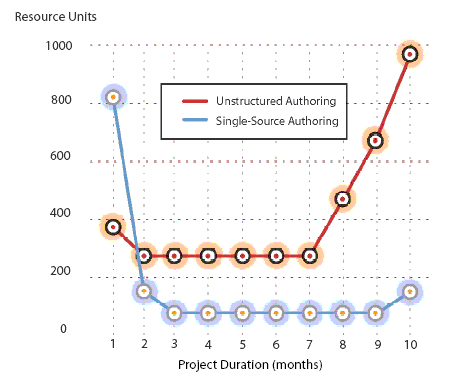
Source: Adobe FrameMaker Tips and
Techniques
The most important structured authoring technique is letting go of
the old idea of control of layout, structure and format. Structured
authoring can be liberating, rather than restrictive. Technical writers no
longer have to worry about widow-lines, kerning, heading styles, bolding,
page layout and auto-numbering!
Structured Authoring requires an understanding of the elements of
the schema being used, the purpose of each element, and the rules for
their use. For example, DITA specifies a number of topic types, such as
Task, Concept and Reference. Within DITA, a Task
topic is intended for a procedure describing how to accomplish
a task; lists a series of steps that users follow to produce a specified
outcome; identifies who does what, when, where and how . A
Reference topic is for topics that describe command syntax,
programming instructions, other reference material; usually detailed,
factual material .
The design of a document is also quite different. Many technical
writers use a brainstorming technique to create a document skeleton, and
then create a proposed table of contents or document structure, before
starting to write the content. This technique does not work as well for
structured authoring; particularly for DITA, where documents are a
collection of numerous "topics", rather than a small number of larger
chapters. "Atomising" or "granularising" the information into smaller
chunks becomes another important structured authoring technique.
The application of metadata is also a new challenge for many
writers. Although indexing may be a familiar task, applying metadata as
topics are being created requires more discipline.
Presentation and Delivery
If XML separates content from presentation from delivery, so that
writers can concentrate on writing, who will be responsible for
presentation? And for delivery? And how is the content integrated with the
presentation and delivery mechanism?
A new role, perhaps with a title of "information architect", is
likely to take up the presentation and delivery responsibilities. The role
is quite a technical one, but still requires an understanding of language,
readability and communication. XML content is transformed to suit a
delivery mechanism through another XML technology called XSLT. The acronym
stands for XML Stylesheet Language - Transformations, and is a cross
between a database query language and a macro-programming language. XSLT
can instantly transform DocBook XML into HTML, or into another XML
language (such as WML or AML), or into an organisation chart graphic
(using SVG), or even into RTF! Information can be sorted, or selected
based on metadata criteria. A related technology called XSL-FO can be used
to transform XML content into print outputs such as PDF and
PostScript.
For Web delivery, CSS still has a role. In most browsers, XML
documents are CSS-aware. It is possible to display an XML document in an
appealing format without transforming to HTML by simply applying an
appropriate CSS stylesheet.
JavaScript and server-side scripting languages are also XML-aware,
so XML content can be transformed by a Web server or as a Web Service.
(But let's not get into Web Services now! That's a whole new XML
field!)
Re-Using Content and Single-Sourcing
One of the benefits of granularised content (smaller chunks), when
coupled with the power of XML transformations, is that a blob of content
can be written once and re-used many times.
XML is by nature a true single-source environment. With content
completely separated from presentation and delivery, it becomes easy to
generate different outputs simply by applying a different transformation.
By connecting the XML content to one XSLT file you might generate WML.
Connecting to another might produce an HTML Help file.
Not Constraining: Liberating
It is important to understand that XML rules are not intended to be
constraining. The X in XML stands for extensible. The rules can
accommodate all sorts of information, and ways of expressing that
information. So XML languages, or standards, can be created to accommodate
all sorts of information. And so they have been.
Structured authoring results in increased productivity, greater
consistency and improved standardisation. In a world where technical
writers have greater demands put upon them, structured authoring offers an
opportunity to deliver higher quality for less effort.
Conclusion
Creating documentation within a structured authoring process is an
exciting challenge for technical writers. Structured authoring is a
necessary consequence of the move to XML schemas for storage and delivery
of technical and procedural documentation. The benefits of providing a
semantic framework for documents are many, and writers can concentrate on
writing rather than presentation and delivery.
Using XML, technical writers can improve the quality of information,
and reduce the quantity of unnecessary information.
Semantically-based structured authoring techniques can result in better
documentation, provided we learn how to use those techniques wisely and
properly.

